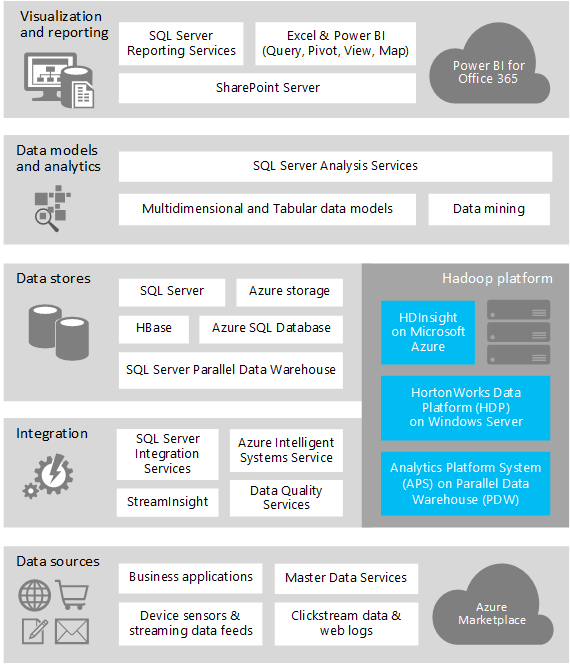
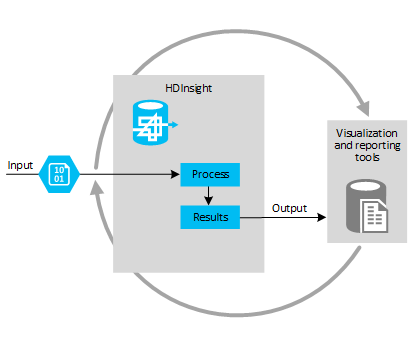
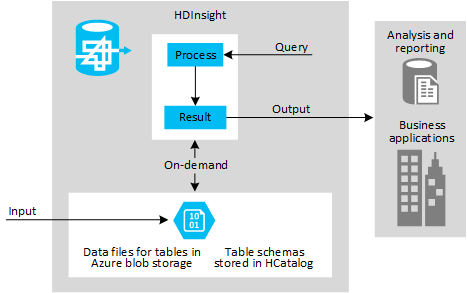
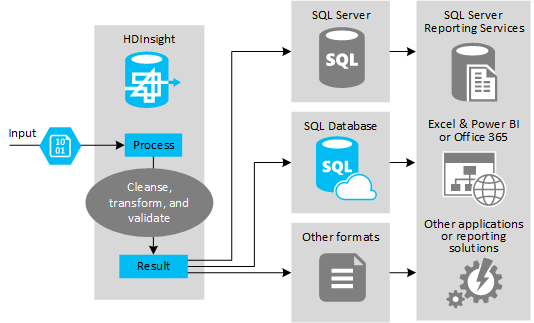
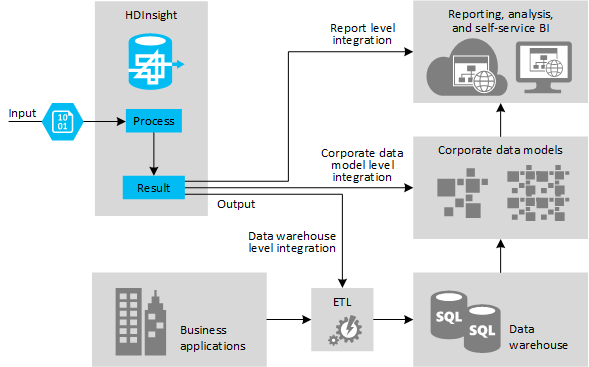
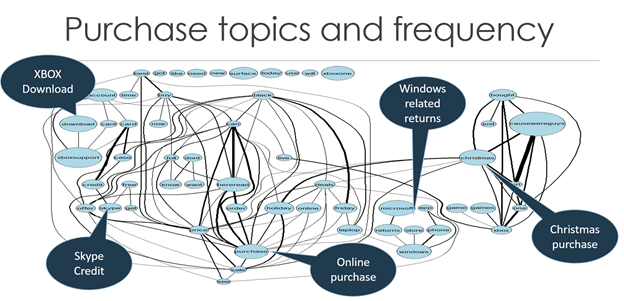
This model is typically chosen for experimenting with data sources to discover if they can provide useful information, and for handling data that you cannot process using existing systems. For example, you might collect feedback from customers through email, web pages, or external sources such as social media sites, then analyze it to get a picture of user sentiment for your products. You might be able to combine this information with other data, such as demographic data that indicates population density and characteristics in each city where your products are sold.